>說明:跟著learnopengl的內容學習,不是純翻譯,只是自己整理記錄。>強烈推薦原文,無論是內容還是排版。 [原文鏈接](http://learnopengl.com/#!Getting-started/OpenGL)本文地址:http://blog.csdn.net/aganlengzi/article/details/50354237
并不簡單的三角形繪制
在OpenGL的世界中,一切都是在三維空間中的,但是屏幕和窗口是二維的像素數組。所以OpenGL的一大工作就是將三維坐標轉換為適合屏幕顯示的二維像素。這個把三維坐標轉換為二維坐標的過程是由OpenGL的圖形渲染流水線來管理的。這個圖形渲染流水線分為兩大部分:首先是將三維坐標轉換為二維坐標;其次是鍵二維坐標轉換為真正的有顏色值的像素。在本次教程中,我們將會簡單地討論這個圖形渲染流水線以及我們應該怎樣使用它來幫助我們創建一些酷炫的像素出來。
注意一個二維坐標和一個像素點是不同的。一個二維坐標是一個點在二維空間中的精確表示,但是一個二維的像素點是一個二維空間中的點在屏幕分辨率的限制下的一個近似表示。
圖形渲染流水線以一組三維坐標為輸入,把它們轉換成屏幕上著色的二維像素點。圖形渲染流水線又可以分成許多步驟,每個步驟都是以前面步驟的輸出作為當前步驟的輸入。每一個步驟都是專用的,它們具有特定的功能,這方便了并行執行。因為這種并行特性,當今顯卡基本上都包含成千上萬個小的處理核心,這些核心幫助我們在GPU圖形渲染流水線中的每個步驟中利用小的程序來快速處理數據。而這些在每個核心上面跑的小程序就叫做著色程序(shaders)。
在這些shader中,有一些是可以被開發者配置的,這些可配置的shader允許我們用自己寫的shader來替換默認的shader。這給了我們對這個流水線的某些部分更細粒度的控制權,因為它們是在GPU上運行的,這或許也能夠幫助我們節省寶貴的CPU時間。shader是用GLSL(OpenGL Shading Language,簡稱GLSL)語言開發的,我們將在下個教程中了解更多關于GLSL的知識。
下面這幅圖展示的是對圖形渲染管線所有階段的一個抽象表示,其中藍色的部分代表我們可以注入自己的shader,應該就是可以自己配置的意思。這里的圖借鑒了
如你所見,這個圖形渲染管線中包含了很多階段,每個階段完成從頂點數據項最終顯示像素點的一部分特定的工作。我們將會以一個簡化的方式簡短地解釋其中的每個階段,目的是讓你有一個對這個流水線工作方式的整體把握。
作為輸入,我們把數組中能構成一個三角形的三個三維坐標值(稱作頂點數據,Vertex Data)傳遞進這個流水線;頂點數據實際上就是所有頂點的集合,而每個頂點實際上就是每個三維坐標系中表示這個頂點的數據。實際上,我們用于表示一個點的數據中可以包含我們想要包含的屬性,但是為了簡化起見,在本例中,我們假設每個頂點只包含這個頂點的三維坐標和頂點的顏色值。
為了讓OpenGL知道你想用這些頂點數據或者顏色值繪制什么圖形,你需要指定你想用這些數據繪制的圖形類型:是需要用它們繪制一些獨立的點,還是需要用它們繪制三角形,或者是用它們繪制一條長長的線?點,三角形或者線,這些稱作圖元,是在任何繪制命令調用前需要告訴OpenGL的,也只有這樣,OpenGL才知道在下一個狀態用繪制命令和給定的數據繪制什么。指定的方式是通過前面說的狀態設置函數完成的,這在后面具體用到的時候會說明。而OpenGL支持的圖元類型永宏表示,比如GL_POINTS,GL_TRIANGLES和GL_LINE_STRIP。
好的,以上圖為例,假設我們已經指定了要繪制三角形,并且已經輸入了頂點數據(包含三個頂點的位置坐標和顏色值),下面真正進入圖形渲染流水線:
流水線的第一階段是頂點處理器,它以單獨的頂點(在本例中包含位置坐標和顏色值)作為輸入,完成的主要功能是將頂點的三維坐標轉換成另一種三維坐標(后面具體會講到),還有就是對頂點的屬性做一些基本的處理。
圖元裝配階段,以所有頂點處理器處理過的的頂點為輸入(如果在前面指定的繪制的內容是GL_POINTS的話,那么就以單個頂點作為輸入),生成一個圖元并且根據圖元的形狀放置所有的頂點。在本例中就是構成一個三角形圖元,而且將這個三角形的各個頂點放到該放的位置。
圖元裝配的輸入作為幾何處理器的輸入。幾何shader以形成圖元的頂點幾何為輸入,它能夠生成新的頂點形成新的圖元(不僅限于前面指定的圖元,比如像本例中的三角形)。在本例中,它從給定的三角形(圖元裝配階段的輸出)中又生成了一個三角形。
幾何處理器的輸出被傳遞給光柵化階段作為輸入。光柵化階段完成圖元和最終要顯示屏幕的對應像素之間的映射,它生成片段處理器用到的片段。在將這些片段輸出到片段處理器之前,裁剪被首先執行。裁剪操作將所有超出顯示范圍的片段都去除,這樣可以提高性能。
在OpenGL中,一個片段就是OpenGL渲染一個像素點需要的所有數據。
片段處理器最主要的作用是計算像素點最終的顏色,這個階段也是所有高級OpenGL效果施展的地方。通常,片段中包含3D場景的數據(比如說光照、陰影和光照顏色等等),這些數據被用來計算出最終的像素顏色值。
在所有相關的顏色值都被確定后,最終的對象將會被傳遞到下一個階段,我們稱其為alpha通道測試和混合階段。這個階段檢查片段的深度值和模板值(我們后面會了解到),并且用他們來檢查這些生成的片段是否在其它對象的前面或者后面,如果在其它對象的后面,即被其它對象遮擋,那么這個片段就會被裁減掉。這個階段也會檢查alpha值(alpha值定義了一個對象的透明度)并且進行對象的混合操作(根據透明度的不同生成不同的效果)。所以即使一個像素的顏色值是在片段處理器階段就生成的,但是到最終顯示的時候,還是有可能完全不同(因為在這個階段還會和其它對象進行相互作用,比如透明遮擋等等)。
如你所見,圖形渲染流水線是相當復雜的,而且包含了很多可配置的部分(圖中藍色著色的階段)。但是,我們大部分只關心頂點和片段處理器。幾何處理器雖然是可選的,但是經常被設置為默認的。
在現代OpenGL中,我們需要自己至少定義一個頂點處理器(處理程序,shader)和一個片段處理器。因為在GPU中沒有默認的頂點或者片段處理程序供我們選擇。基于此,通常開始學習現代OpenGL是非常困難的,因為僅僅是渲染我們的第一個三角形都需要大量的相關知識。但是一旦你成功渲染了你的第一個三角形,你將會學到更多的OpenGL圖形編程知識。
下面我們就來渲染我們的第一個三角形吧~
##頂點輸入開始繪制之前我們首先要給OpenGL一些頂點數據。OpenGL是一個三維圖形庫,所以所有的坐標都應該是三維的,即包含x,y和z坐標。OpenGL不會簡單地將你的三維坐標轉換成屏幕上的二維像素。前面已經提到過,OpenGL中的坐標是標準化設備坐標系,即在x,y和z方向上都是-1到1之間的立方體。所有在這個標準化設備坐標系中的坐標才是可以顯示在屏幕上的,而在這個標準化設備坐標系之外的坐標都不可能顯示。因為我們想要渲染一個三角形。所以我們總共需要提供構成這個三角形的三個點的三維坐標值。我們利用一個GLfloat類型的數組定義他們在標準化設備坐標系的可見區域。
GLfloat vertices[] = {-
0.5f , -
0.5f ,
0.0f ,
0.5f , -
0.5f ,
0.0f ,
0.0f ,
0.5f ,
0.0f
};
因為OpenGL在三維空間中進行處理,但是我們希望渲染的是一個二維的三角形,所以我們將三個頂點的坐標值中的z值全部都設置為0.0。這樣的能夠使三角形的深度之保持一致,看上去像一個二維圖形一樣。>####標準化設備坐標系 Normalized Device Coordinates (NDC)當你的頂點坐標在頂點處理器中處理過,它們就應該在標準化設備坐標系中。標準化設備坐標系是一個小的立方體空間中,這個立方體的三個維度上(x,y和z)都在-1到1之間。任何在這個范圍之外的坐標都不會在屏幕上顯示。下圖中可見在標準化設備坐標系統我們上面定義的三角形(先不考慮z軸,可以認為z軸是垂直于紙面的)。
通常的屏幕坐標系的原點是在屏幕的左上角上,而且y正軸是自原點垂直向下的。在標準化坐標系中卻不同,其原點在正中,y軸垂直向上。最終你會希望你繪制的所有的對象的坐標都在這個標準化設備坐標系之內,否則它們不會被顯示出來。你的標準化設備坐標最終都會被轉換成屏幕坐標系中的坐標。這個轉化過程是基于在程序中你設置的glViewport參數來完成的。生成的屏幕坐標系中的坐標被轉換成片段并輸入到片段處理器。上面我們已經完成了三角形頂點數據的定義,現在我們想要將這些數據作為圖形渲染流水線的第一階段的輸入,也就是頂點處理器的輸入。為此,我們需要在GPU中申請內存來存儲這些頂點數據、告訴OpenGL應該如何解釋這塊內存并且指定應該如何將這些數據發送到顯卡。之后頂點處理器就可以從內存中處理我們指定數量的頂點了。我們利用所謂的頂點緩存對象(vertex buffer objects,簡稱VBO)來管理這塊內存。VBO能夠在GPU的內存中存儲大量的頂點。利用這種緩存對象的好處是我們可以一次就發送大批量的數據到顯卡,而不用每次之傳輸一個頂點。畢竟從CPU向顯卡中傳輸數據是非常慢的,所以我們總是找機會一次傳輸盡可能多的數據。一旦數據存儲在顯卡內存中,頂點處理器對這些數據的訪問可以看成是瞬時的,這極大提升了頂點處理器的處理速度。VBO是我們在這個教程中遇到的第一個OpenGL對象。像OpenGL中的其它對象一樣,它有一個ID唯一的表示一個緩沖區,所以我們可以像下面這樣用glGenBuffers創建一個VBO。
GLuint VBO;
glGenBuffers(1 , &VBO) ;
OpenGL的緩沖區對象有多種緩沖區類型,頂點緩存區對象的緩沖區類型是GL_ARRAY_BUFFER。我們通過下面的方式使用glBindBuffer將新生成的緩存區綁定到GL_ARRAY_BUFFER目標類型。
glBindBuffer(GL_ARRAY_BUFFER, VBO) ;
此后,我們對任何緩沖區的調用(以GL_ARRAY_BUFFER為目標類型),都會被用于當前綁定的緩沖區,即VBO。于是我們可以通過調用glBufferData函數來將之前定義的頂點數據拷貝到這個緩沖區內存中:
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices) , vertices, GL_STATIC_DRAW) ;
glBufferData函數負責將用戶定義的數據拷貝到當前綁定的緩沖區中,它的第一個參數是我們想要拷貝進數據的緩沖區類型:在本例中頂點緩沖區對象當前被綁定到了GL_ARRAY_BUFFER目標類型。第二個參數指定了我們想要傳輸進緩沖區的數據量大小(以字節為單位),即使用運算符sizeof對我們定義的數組計算值。第三個參數指定我們想要傳輸的數據。第四個參數指定了我們想要讓顯卡怎樣來管理這些給定的數據(我感覺是高速顯卡我們可能怎樣操作這些數據,在其進行存儲的時候,為提高性能或者節省能耗而“心里有數”),它有三種形式:
GL_STATIC_DRAW :
這些數據基本上不會改變或者極少情況下會被改變。
GL_DYNAMIC_DRAW :
這些數據可能會經常被改變。
GL_STREAM_DRAW :
這些數據在每次繪制的時候都會被改變。
三角形三個點的位置數據不會改變,在每次渲染的時候都保持在原來的位置,所以應該被設置為GL_STATIC_DRAW。舉例來說,如果緩沖區中的數據會經常改變,那么使用GL_DYNAMIC_DRAW或者GL_STREAM_DRAW參數將會讓顯卡將這些數據分配到能夠更快寫入的地方(以提高性能)。到目前,我們通過頂點緩沖區對象(VBO)將頂點數據存儲到了顯存中。接下來我們想要創建一個頂點處理程序和片段處理程序。>說明:頂點處理器聽上去像是GPU中的硬件名稱,這里之所以這么翻譯,是想和下面的頂點處理程序區別。實際上,頂點處理程序完成的就是上面圖形渲染流水線中頂點處理器完成的功能。這樣翻譯便于理解。實際上原文中上面的和下面的都叫做vertex shader。如果都翻譯成頂點處理程序,那么上面流水線的一個階段是頂點處理程序,怪怪的。所以這樣翻譯。##頂點處理程序 vertex shader頂點處理程序是我們可以編程的流水線中的一個部分。現代OpenGL要求我們,如果想要進行渲染,至少要建立起頂點處理程序和片段處理程序。所以我們將會簡短介紹處理程序而且配置兩個非常簡單的shaders來繪制我們的第一個三角形,在下一個教程匯總將會討論關于shader的更多細節。我們首要做的是利用shader語言GLSL來寫我們的頂點處理程序并且編譯這個shader以便于我們可以再我們自己的程序中使用。下面我們將看到一個用GLSL寫的非常基本的vertex shader。
#version 330 core layout (location =
0 )
in vec3 position;
void main()
{
gl_Position =
vec4 (position.x, position.y, position.z,
1.0 );
}
正如你所見,GLSL和C類似。每個shader的開頭都會定義它的版本,330對應著OpenGL3.3,420對應著OpenGL4.2。我們還明確地聲明我們使用core-profile模式。接下來我們聲明了這個頂點渲染程序的頂點屬性輸入,以關鍵字in標明的position。因為目前我們只關心位置,所以只需要指定單獨這個頂點屬性作為輸入就夠了。GLSL中,有一個可以包含1到4個GLfloat類型的vector數據類型。因為三角形的每個頂點都是一個三維坐標,所以我們可以使用vec3類型的vector(vec3表示vector中含有3個GLfloat)來定義名稱為position的輸入。我們同時還通過layout關鍵字和location的值(本例設置為0)明確地指定這些輸入數據的位置。這在后面告訴GPU我們用的數據在哪兒的時候會用到。>這個程序可以這么理解:聲明類型為vec3的變量position,用關鍵字in指明這是此頂點處理器的輸入,并且用關鍵字layout(location = 0)指明輸入數據的索引號,便于后面查找。然后是函數體。>>矢量Vector在圖形編程中我們經常使用數學中矢量的概念,因為矢量可以很優雅地在任何維度內表示對象的位置、方向和其他屬性(所有想要表示的都可以放到一個矢量中)。而且矢量具有很好的數學特定。GLSL中的矢量最多可以含有四個數值,而且可以通過與C結構體中元素類似的訪問方式訪問,如vec.x,vec.y,vec.z和vec.w。它們分別代表了對象在空間中的每一個維度的表示。注意vec.w分量在表示三維空間中的位置時是不需要的。但是它用于稱作透視圖處理中。在后面的教程中應該會對vector有更深入的講解。在程序中,設置頂點處理程序的輸出到在圖形渲染流水線中已經定義好的gl_Position變量中。它是一個vec4類型的變量。這個gl_Position理解成是定點處理器和下一個階段圖元裝配的接口。因為上面我們設置的輸入是3維矢量,我們需要把它轉化成4維矢量。妝花方式比較簡單,即利用vec4的構造函數來生成四個分量已經指定的一個vec4對象就好了。這里w分量設置為了1,具體原因后面會講到。目前這個頂點渲染程序應該是可以想象到的最簡單的頂點處理程序了。因為它對輸入幾乎什么也沒有做,只是轉換了一下數據類型就作為結果輸出了。在真正的應用程序中,一般輸入的數據不會(像本例中)已經被標準化(所有的坐標值都在標準化設備坐標系中),所以定點處理程序可能首先需要先將這些坐標轉化為OpenGL能夠處理的標準化設備坐標系。>這里需要說明一下,上面寫的定點處理程序(vertex shader)并不是放在單獨一個源文件編譯鏈接執行的程序,它是一個shader程序。只是我們用到的圖形渲染流水線中的一個階段(頂點處理器)中用到的程序。所以它是被存儲在類似于C的字符數組中的。像下面這樣:
const GLchar* vertexShaderSource ="
# version 330 core
\n \
layout (location = 0) in vec3 position;
\n \
void main()
\n \
{ \n \
gl_Position = vec4(position.x, position.y, position.z, 1.0);
\n \
} \n \0";那么怎么將它組裝到我們的圖形渲染流水線中呢?首先編譯,然后組裝。接著向下看吧。##編譯shader我們已經有了頂點渲染程序(像上面那樣存儲在了字符數組中),在使用的時候,我們需要在運行時從它的源碼動態編譯它。為了編譯這個shader,我們需要先創建一個shader對象,同樣需要一個唯一的ID來標識。像下面這樣通過GLuint來存儲ID,通過glCreateShader來創建shader對象:
GLuint vertexShader;
vertexShader =
glCreateShader(GL_VERTEX_SHADER);
需要注意的是,我們需要在調用glCreateShader的時候指定我們想要創建的shader的類型,因為我們創建的是頂點處理程序,所以給的參數是GL_VERTEX_SHADER。接下來我們將上面寫的shader源碼和新創建的這個shader對象綁定。并且通過調用glCompileShader來編譯這個shader:
glShaderSource(vertexShader, 1 , &vertexShaderSource, NULL) ;
glCompileShader(vertexShader) ;
glShaderSource函數的第一個參數是一個shader對象,第二個參數指定傳遞的源碼數量,第三個參數是shader源碼字符數組的指針,第四個參數目前我們先不用管,直接設置為NULL就可以。>實際上完成上面的過程也就完成了一個shader的編譯,不管編譯哪個shader,其原理和做法都是相似的。但是總感覺不是那么放心,編譯成功沒有?錯在哪兒了?以下提供了可以檢查編譯結果的方法:
GLint success;
GLchar infoLog
[512] ;
glGetShaderiv(vertexShader, GL_COMPILE_STATUS, &success) ;
即首先設置一個flag,即success變量,然后設置一個比較大的緩沖區來裝編譯結果輸出信息。最重要的是glGetShaderiv函數,它幫助我們得到編譯結果信息。如果success為0,表示編譯出錯,這時我們應該來獲取錯誤輸出信息,這通過glGetShaderInfoLog來完成:
if (
! success)
{glGetShaderInfoLog(vertexShader,
512 ,
NULL , infoLog);std
::cout << "ERROR::SHADER::VERTEX::COMPILATION_FAILED\n" << infoLog
<< std
::endl ;
}
當然如果編譯成功,就不會有報錯信息,也就是編譯成功了。## 片段處理程序 Fragment shader上面提到,為了渲染三角形,我們還需要提供片段處理程序。片段處理程序提供圖形渲染流水線中片段處理器完成的功能。它負責計算像素點的顏色值。簡化起見,我們的片段處理程序為所有的像素都總是輸出一種顏色——橙色。在計算機圖形中,顏色值是由四個值來表示的:分別是紅、綠、藍和alpha通道分量,通常簡寫為RGBA。在OpenGL和GLSL中,我們通過設置每種分量值(0.0-1.0)來定義一個顏色值。舉例來說,如果我們想要設置黃色,那么我們將紅綠兩個分量設置成1.0。由三種顏色分量我們可以得到16,000,000種顏色值。
#version 330 core out vec4 color;
void main()
{color = vec4(
1.0f ,
0.5f ,
0.2f ,
1.0f );
}
如上面的程序所示,片段渲染程序只輸出一個vec4類型的變量,也就是color,通過out關鍵字來標識。程序的主體部分知識將這個輸出值賦值為橙色。這應該也是一個非常簡單的片段處理器了。編譯片段處理程序的過程和編譯頂點處理程序的過程是十分相似的。只是在調用glCreateShader的時候指定的參數是GL_FRAGMENT_SHADER:
GLuint fragmentShader;
fragmentShader =
glCreateShader(GL_FRAGMENT_SHADER);
glShaderSource(fragmentShader, 1, &fragmentShaderSource, NULL);
glCompileShader(fragmentShader);
>同樣,可以使用上面介紹的方法檢驗我們的編譯是否成功。現在我們已經準備好了我們必須要提供的兩個shader,下面就是要將它們組裝到我們的圖形渲染流水線中(別忘了它們只是整個圖形渲染流水線中的兩個階段),以便于我們使用它來進行渲染。## Shader program整個圖像渲染流水線可以看成是一個渲染程序,它由不同階段的shader構建而成。OpenGL中對應的概念是渲染程序對象(shader program object),它是編譯好和連接到一起的不同階段的shader的整體。這里可以把它看成是可以裝配的流水線。為了使用剛剛編譯好的頂點和片段shader,我們需要把它們裝配到渲染程序對象中并且激活它們。這樣我們才能夠在調用渲染指令的之后使用包含這些shaders的渲染程序對象來渲染我們的圖形。這個過程應該是一個狀態設置過程,而調用渲染命令是狀態使用過程。如上面講到的,在圖形渲染流水線中,前面階段的輸出是后面階段的輸入。同理,在渲染程序對象中,裝配不同的shader的時候也是這樣,將前面階段的shader的輸出作為后面階段shader的輸入,而且其它階段默認已經存在。理解成渲染程序對象會幫我們處理這些就好了。創建一個渲染程序對象是簡單的:
GLuint shaderProgram;
shaderProgram =
glCreateProgram();
glCreateProgram創建了一個程序對象,而shaderProgram保存了其ID,現在我們將我們之前創建并編譯好的兩個shader通過調用glAttachShader和glLinkProgram裝配到這個渲染程序對象中:
glAttachShader(shaderProgram, vertexShader) ;
glAttachShader(shaderProgram, fragmentShader) ;
glLinkProgram(shaderProgram) ;
好的,上面的過程就像是我們組裝了一條生產線,讓人激動的是,其中的兩個模塊使我們自己實現的。它幾乎可以開始生產了,而其產品將會是輸出到屏幕上的圖形。>我們可以像檢查shader程序是否編譯好一樣檢查這條生產線是否組裝好。只不過需要使用與之不同但是十分類似的函數:
glGetProgramiv(shaderProgram, GL_LINK_STATUS, &success);
if (!success) {glGetProgramInfoLog(shaderProgram,
512 ,
NULL , infoLog);
...
}
怎么樣啟動這個生產線呢?我們首先需要告訴OpenGL我們想要激活這個渲染程序對象,這通過函數glUseProgram完成:
glUseProgram(shaderProgram) ;
這樣,在此之后我們調用的任何渲染指令,都會用這個渲染程序(這條生產線)來執行。當然不要忘記在將編譯好的shader裝配到渲染程序對象后刪除它們,因為我們不再需要它們:
glDeleteShader(vertexShader) ;
glDeleteShader(fragmentShader) ;
上面的過程相當于我們已經準備好了生產產品的硬件條件。一條我們定制化(頂點和片段處理器都由我們創建)的生產線(渲染程序對象),而且我們已經準備好了原材料(頂點數據)。我們似乎可以開工生產我們的產品(渲染我們的圖形)了。但是并沒有。OpenGL并不知道它應該如何使用我們的原材料(數據)。比如應該怎樣取出和存入,怎樣將它們和頂點渲染程序中定義的輸入數據聯系起來。下面我們將告訴OpenGL應該怎么使用這些數據。 ##設定頂點輸入方式 前面,我們寫的頂點處理程序只是設定了輸入的類型(vec3)和輸入后的索引(location=0),但是并沒有指明我們的頂點數據的輸入方式。我們的數組中一共有三個頂點9個數據,是下標為2的先輸進去還是下標為0的先輸進去?實際上,在OpenGL中頂點定點渲染程序允許我們以多種方式指定類似的輸入方式,這提供了數據輸入的巨大靈活性,但是也意味著我們需要手工指定我們的頂點數據和頂點處理程序中的頂點屬性的對應關系。即我們需要指定OpenGL在渲染前應該如何解釋或理解這些頂點數據。我們的頂點緩沖區中的數據的個數如下圖所示:
位置坐標值都是32位(4字節)的浮點類型;每個位置由三個坐標值構成;在每組3個坐標值之間沒有任何間隙,換句話說,數值在內存中是連續緊密存放的;數據的第一個值位于緩沖區開始的位置。基于以上這些信息,我們可以通過glVertexAttribPointer函數來告訴OpenGL應該如何解釋這些頂點數據:
glVertexAttribPointer(0 , 3 , GL_FLOAT, GL_FALSE, 3 * sizeof(GLfloat) , (GLvoid*) 0);
glEnableVertexAttribArray(0 ) ;
glVertexAttribPointer函數的參數較多,我們逐一來看一下:第一個參數:指定了我們想要配置哪個頂點屬性(頂點屬性是一個詞,這里可以理解成一個頂點屬性集合,即矢量)。還記得我們在頂點處理程序的開始處指定的輸入的位置頂點屬的location值嗎,就是這個實參0的含義。“layout (location = 0)“就限定了頂點屬性的位置是0,方便我們在這個地方使用的時候易于索引。第二個參數指定了頂點屬性的大小,因為我們設置的輸入是vec3類型的,所以這里設置為3,表示由3個數據構成。第三個參數指定數據的類型,設置為GL_FLOAT。因為GLSL中的vector中的數值類型是GLfloat。第四個參數指定我們是否需要將數據標準化,因為我們的數據在生成的時候就已經標準化了,所以這里并不需要,設置為GL_FALSE。如果設置為GL_TRUE,所有不滿足數值大小范圍為[-1,1]的數值都會被首先標準化為標準化設備坐標系中的坐標值。第五個參數指定了在連續頂點屬性集合之間的空隙——稱作步進長度。我們的例子中每兩個頂點屬性之間相差三個GLfloat空間,所以設置為“3 * sizeof(GLfloat)“,實際上,因為這里數據都是緊密排列的,設置為0,OpenGL就會認為頂點屬性之間沒有空隙,也是能夠正常解析的。最后一個參數將0轉換為GLvoid*類型,它指明了數據在緩沖區中的偏移。上面已經說了,我們例子中的數據在緩沖區中的偏移是0,所以這里這么給實參。>還記得前面講的VBO嗎?實際上,上述頂點屬性的取得都要經過VBO,因為VBO是OpenGL和Memory之間的接口。那么在有多個VBO時,哪一個才是我們要取的呢?也就是說,如果我們設定的取數據的地方不是我們想象的,而是其他的VBO呢?實際上,在每次取數據的時候,程序能看到的VBO只有一個,也就是綁定到 GL_ARRAY_BUFFER目標的那個VBO。那么,如果我們想要從其他VBO中取數據也是簡單的,只需要在取之前將含有我們想要數據的VBO綁定到 GL_ARRAY_BUFFER就好了。到目前為止,我們已經指定好了OpenGL應該怎樣解釋我們的原材料(頂點數據)。我們還應該通過上面所示的glEnableVertexAttribArray函數設置頂點屬性生效,因為頂點屬性默認是disabled的,參數就是設置的location(為0)。OK,到這兒基本上所有該準備的都已經準備完成了!我們首先利用VBO準備好了頂點數據,接著創建了兩個shader(頂點和片段),然后將它們裝配到當前使用的渲染程序對象中,最后我們告訴OpenLGL應該如何解釋我們的數據。是時候繪制我們的圖形了。至此,我們知道了渲染圖形的整個流程大致是這么個樣子:
glBindBuffer(GL_ARRAY_BUFFER, VBO) ;
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices) , vertices, GL_STATIC_DRAW) ;
glVertexAttribPointer(0 , 3 , GL_FLOAT, GL_FALSE, 3 * sizeof(GLfloat) , (GLvoid*) 0);
glEnableVertexAttribArray(0 ) ;
glUseProgram(shaderProgram) ;
someOpenGLFunctionThatDrawsOurTriangle() ;
在繪制之前,還有最后一步——更標準地繪制我們的三角形! 在每一次我們想要繪制一個對象的時候,這個流程都需要執行一次。現在看上去可能不是那么多,但是,如果后面我們的繪制更加復雜的時候就會出現問題了。快速綁定合適的緩沖區對象和配置所有的頂點屬性變成一個龐雜的過程。要是能有一個對象將我們配置的所有的狀態都記錄下來,只要在使用的時候綁定這個對象就好了。這種對象就是下文要講到的頂點數組對象(Vertex Array Object,簡稱VAO)。##頂點數組對象 Vertex Array Object 頂點數組對象(VAO)可以像VBO類似方式綁定,隨后的對數組對象的調用都將被存儲到頂點數組對象中。這樣的好處是,在進行頂點屬性指針配置的時候只需要調用一次必要的函數,再次使用的時候,只需要綁定相關的VAO就可以了,因為VAO已經將這個配置全部記錄下來。這樣的話,在不同的對象繪制之間就簡化了配置的過程。因為我們設置要繪制對象的狀態設置都已經存儲到了VAO中。OpenGL的core-profile模式要求我們使用VAO,這樣的話它能夠知道對我們的頂點輸入的具體操作。如果我們綁定VAO失敗,OpenGL很有可能停止運行。一個頂點數組對象(VAO)存儲以下信息:對glEnableVertexAttribArray或者glDisableVertexAttribArray調用對頂點屬性的配置,即對glVertexAttribPointer的調用通過調用glVertexAttribPointer與頂點屬性關聯的VBO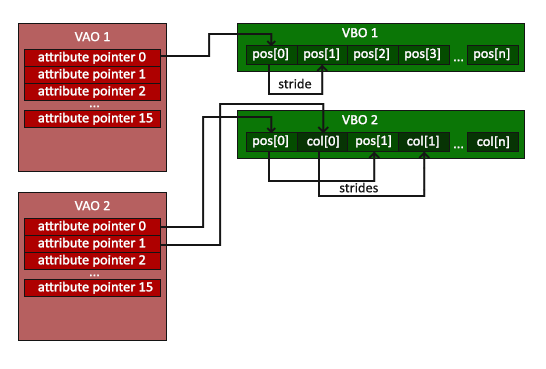創建VAO的過程和創建VBO類似:
GLuint VAO;
glGenVertexArrays(1 , &VAO) ;
使用VAO時唯一要做的就是使用glBindVertexArray函數來綁定VAO。綁定之后我們應該綁定或者配置相關的VBO和屬性指針,然后解綁這個VAO留作后用。在我們想要繪制一個對象的時候,我們只需要將包含我們想要的設置的VAO在繪制之前再次綁定就可以了。這個過程大概如下所示:
glBindVertexArray(VAO) ;
glBindBuffer(GL_ARRAY_BUFFER, VBO) ;
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices) , vertices, GL_STATIC_DRAW) ;
glVertexAttribPointer(0 , 3 , GL_FLOAT, GL_FALSE, 3 * sizeof(GLfloat) , (GLvoid*) 0);
glEnableVertexAttribArray(0 ) ;
glBindVertexArray(0 ) ;
[...]
glUseProgram(shaderProgram) ;
glBindVertexArray(VAO) ;
someOpenGLFunctionThatDrawsOurTriangle() ;
glBindVertexArray(0 ) ;
>通常在每次配置之后將對象解綁是一個比較好的做法,因為這樣可以防止在其它地方對其無意之間的綁定。終于,所有的東西都已經準備好了,實際上在VAO講解之前就已經好了,只不過我們對自己的要求比較高,要用更規范的方式來進行我們圖形的繪制。實際上利用VAO的方式也的確方便我們后面的學習和理解。而且當我們有很對對象或者很多VBO或者很多配置需要時常切換的時候,我們利用VAO可以大大提高工作效率。嗯,這是值得的!##期待已久的三角形!我們通過OpenGL提供的圖元繪制函數glDrawArrays(實際上還有其他,我們現在先選擇glDrawArrays)來繪制我們的對象。相關的VAO,VBO就是前面花了這么長時間準備的:
glUseProgram(shaderProgram) ;
glBindVertexArray(VAO) ;
glDrawArrays(GL_TRIANGLES, 0 , 3 ) ;
glBindVertexArray(0 ) ;
glDrawArrays函數的第一個參數是OpenGL支持繪制的圖元類型的宏定義。GL_TRIANGLES代表三角形。 第二個參數指定了開始繪制的頂點數組下標,我們就讓它為0。最后一個參數指定了我們要繪制多少個點,我們只有三個點。現在試著編譯我們的程序并且運行吧,我已經迫不及待了。我的運行的結果是:
到目前為止,全部的代碼在這兒。
##元素緩沖對象 Element Buffer Objects除了上面介紹的利用glDrawArrays函數進行圖形渲染的方式,實際上還有一種渲染方式,就是借助glDrawElements進行圖形渲染。它和元素緩沖對象(Element Buffer Objects,簡稱EBO)是聯系在一起的。解釋元素緩沖對象(EBO)是如何工作的最好方式是給出一個例子:假設我們想要繪制一個矩形而不是三角形。我們可以利用兩個三角形(OpenGL主要是利用基本圖元三角形來完成復雜對象的繪制)來繪制一個矩形。按照上面講過的流程,首先是數據的產生:
GLfloat vertices[] = {
0.5f ,
0.5f ,
0.0f ,
0.5f , -
0.5f ,
0.0f , -
0.5f ,
0.5f ,
0.0f ,
0.5f , -
0.5f ,
0.0f , -
0.5f , -
0.5f ,
0.0f , -
0.5f ,
0.5f ,
0.0f
};
如你所見,兩個三角形之間是有所重合的:左上角和右下角的點被指定了兩次。相對于一個矩形的四個頂點來說,我們指定了六個點(其中有兩個是重合的),這相當于多做了50%的工作!當我們要繪制更為復雜的模型的時候這種情況還會更糟,因為它們可能有更多的重合。是不是能有一種方法只需要存儲(矩形)模型的不同的點,在繪制的時候只需要指定特定的繪制順序就能夠得到我們想要的圖形呢?在這種情況下,我們只需要存儲矩形的四個頂點(右上,右下,左上,左下),且每個頂點存儲一次,而且只需要在繪制的時候指定先繪制右上–右下–左上一個三角形,在繪制右下–左下–左上一個三角形就可以了。OpenGL會提供給我們這種方便的方式嗎?幸運的是,元素緩沖對象(EBO)就是干這個事的!EBO是一個像VBO一樣的緩存區,但是它存儲的是OpenGL需要繪制的頂點的索引(而不是坐標)。這種稱作為索引繪制的方法解決了上述的重復的問題。為了使用這種方法,我們需要首先設定頂點的坐標值和我們期望OpenGL在繪制的時候的索引值,它們是兩個數組,如下所示:
GLfloat vertices[] = {
0.5f ,
0.5f ,
0.0f ,
0.5f , -
0.5f ,
0.0f , -
0.5f , -
0.5f ,
0.0f , -
0.5f ,
0.5f ,
0.0f
};
GLuint indices[] = {
0 ,
1 ,
3 ,
1 ,
2 ,
3
};
如代碼所示,我們僅僅在頂點坐標的數組中指定了我們想要繪制的矩形的四個頂點,而在索引數組中指定了在繪制每個三角形時使用的點。接下來我們來創建元素緩沖對象:
GLuint EBO;
glGenBuffers(1 , &EBO) ;
創建過程和VBO的創建過程是一致的,因為二者本質上就是一塊緩存區。同樣像VBO一樣,可以使用glBindBuffer來指定EBO的緩沖區類型,可以使用glBufferData將索引數組的數據復制到這塊緩沖區中。同樣,和VBO綁定到GL_ARRAY_BUFFER目標類似,我們將EBO綁定到GL_ELEMENT_ARRAY_BUFFER目標,以保證調用相關的函數的時候操作的是我們現在生成的這個索引數組:
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO) ;
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices) , indices, GL_STATIC_DRAW) ;
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO) ;
接下來,我們需要調用另一個繪制函數glDrawElements來完成這個矩形的繪制。調用glDrawElements表明我們想要按照我們當前綁定的EBO中的索引值來繪制我們的圖形。如下所示:
glDrawElements(GL_TRIANGLES, 6 , GL_UNSIGNED_INT, 0 ) ;
glDrawElements函數的第一個參數指定了我們想要繪制的圖元類型,這里指定為GL_TRIANGLES,第二個參數是要繪制的元素個數。這里設置為6因為我們要繪制兩個三角形(2*3=6個頂點,就是索引數組中的六個頂點)。第三個參數指定了索引的數據類型,這里設置的是無符號整型GL_UNSIGNED_INT,最后一個參數允許我們指定EBO中的一個偏移(或者在不用EBO的時候這個參數直接給一個索引數據名),這里我們給定的值是0。glDrawElements函數從當前綁定到GL_ELEMENT_ARRAY_BUFFER目標的EBO中取得索引值。這意味著我們在每次繪制對象的時候都需要綁定相應的EBO到GL_ELEMENT_ARRAY_BUFFER,這看上去似乎又有些繁雜。恰好之前介紹過的VAO也同樣能夠幫助我們解決這個問題。一個頂點數組對象(VAO)也可以保留EBO的綁定信息(和VBO類似)。所以如果在綁定VAO之后進行了EBO的綁定也會被VAO記錄下來,等到再次綁定VAO的時候,同樣相應的EBO也就被綁定到了相應的GL_ELEMENT_ARRAY_BUFFER。如下圖所示: 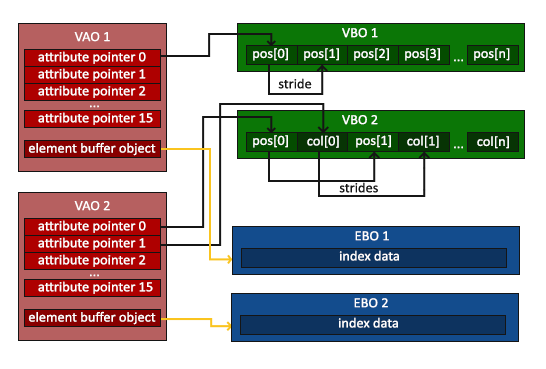>VAO在綁定目標是GL_ELEMENT_ARRAY_BUFFER存儲glBindBuffer調用。這意味著它也存儲它的解綁調用,以確保你在解綁VAO之前不會解綁EBO,否則,它就沒有EBO來進行配置了。利用EBO、VAO和glDrawElements的初始化和繪制代碼基本流程如下所示:
glBindVertexArray(VAO) ;
glBindBuffer(GL_ARRAY_BUFFER, VBO) ;
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices) , vertices, GL_STATIC_DRAW) ;
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO) ;
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices) , indices, GL_STATIC_DRAW) ;
glVertexAttribPointer(0 , 3 , GL_FLOAT, GL_FALSE, 3 * sizeof(GLfloat) , (GLvoid*) 0);
glEnableVertexAttribArray(0 ) ;
glBindVertexArray(0 ) ;
[...]
glUseProgram(shaderProgram) ;
glBindVertexArray(VAO) ;
glDrawElements(GL_TRIANGLES, 6 , GL_UNSIGNED_INT, 0 )
glBindVertexArray(0 ) ;
運行上面的程序應該得到如下所示的畫面。左邊的圖形看上去應該是比較熟悉的填充模式,右邊的方式是用線框模式繪制的。線框的三角形顯示出這個矩形確實是由兩個三角形組成的。
線框模式和填充模式 以線框模式繪制三角形(或者其它圖元),需要利用狀態設置函數glPolygonMode(GL_FRONT_AND_BACK, GL_LINE)來完成,其中第一個參數指定對要繪制的圖元的兩個面(OpenGL中的繪制對象都是有兩個面的,正面和反面,后面應該會講到怎么區分這兩個面)都采用同樣的繪制模式,第二個參數指定以線框來繪制圖元。隨后的繪制命令都會以設定的線框模式來繪制圖形,知道我們將繪制模式再次通過glPolygonMode函數將繪制模式指定為填充模式。
錯誤是不可避免的,如果有錯誤,說明前面的某一步可能出問題了。同時,也代表理解上可能有點問題,當然也有可能是我表述不清。。。。可以回過頭來檢查一下,到目前為止的多有代碼都在這兒。值得注意的是,代碼中為了和glDrawArrays繪制方式區別,以索引繪制的方式為其創建了另一份對應的VBO,EBO和VAO,所以有多個VBO和VAO,這樣在切換的時候可以體會利用VAO進行狀態設置保存的好處。
如果你按照上面的過程成功繪制了三角形或者矩形。你已經挺過了學習現代OpenGL幾乎是最艱難的一段:繪制一個簡單的三角形。萬事開頭難嘛。實際上,這其中包含了很多相關的知識,如果沒有學過圖形學相關的內容,看起來還是比較吃力的。如果有相關的圖形學基礎,可以發現,本次教程是對理論知識的一次小小實踐。充分地理解這個過程是十分必要的,也是后面繼續學習的基礎。一旦對這些概念和過程有了充分的了解,后面的內容應該就相對簡單一些了。
總結
以上是生活随笔 為你收集整理的【Modern OpenGL】第一个三角形 的全部內容,希望文章能夠幫你解決所遇到的問題。
如果覺得生活随笔 網站內容還不錯,歡迎將生活随笔 推薦給好友。
