一起来DIY一个人工智能实验室吧
閱讀原文
摘要:?俗話說,工欲善其事,必先利其器,這篇文章我們將告訴大家如何搭建一個AI實驗室,并穿插一些小Demo,為后面的AI學習實踐做好準備。
一、DIY一個AI實驗室:
原材料的選擇
我們的AI入門課程已經講過兩節了,前面我們講了AI的概念、算法、工具等內容,第三節我們會介紹一些實際操作的內容。俗話說,工欲善其事,必先利其器,這篇文章我們將告訴大家如何搭建一個AI實驗室,并穿插一些小Demo,為后面的AI學習實踐做好準備。
現在可供選擇的AI開發框架很多,推薦大家從Tensorflow開始上手,原因后面會說。另外,在“高階版”的AI實驗室中,我們使用了Kubernetes + Docker做分布式訓練的運行環境,所以推薦各位同學使用64位的Ubuntu 16.04或更高版本的操作系統。如果只是想玩玩“單機版”,那也可以使用Windows和Mac,操作過程和Ubuntu差別不大。
AI實踐肯定要寫程序,各位同學肯定都有自己喜歡的IDE或者編輯器,但是編寫AI程序,和編寫其他程序有個很大的區別,那就是這些程序都需要實時的輸出一些圖表以供調試或者查看運行結果,我們之前用的大多數開發工具都沒有這個能力,所以現在大家都用Jupyter Notebook來做AI程序、尤其是機器學習程序的開發。
綜上,我們將使用Tensorflow、Kubernetes和Jupyter Notebook做AI實驗室的“原材料”,下面我們分別說下選型依據。
二、搭建“單機版”的AI實驗室
搭建“單機版”的AI實驗室非常簡單,只要三步即可:
安裝Python和Virtualenv,這里我們使用Python3:
sudo apt-get install python3-pip python3-dev python-virtualenv
創建并激活Virtualenv環境(工作目錄名為AILab,也可以換個自己喜歡的名字):
virtualenv --system-site-packages -p python3 AILab
source AILab/bin/activate
安裝Tensorflow和Jupyter Notebook,以及用來調試Tensorflow程序的Tensorboard插件:
pip3 install tensorflow
pip3 install jupyter
pip3 install jupyter-tensorboard
這里我們使用了Virtualenv,以免搞亂潔癖碼農的Python環境。上述步驟完成后,在Virtualenv的提示符下執行:
(AILab)$ jupyter notebook
即可啟動Jupyter Notebook
如果有同學需要使用GPU,那么還需要安裝NVIDIA的CUDA工具包、cuDNN和分析工具接口,會比較麻煩。
有需要的同學可以參考鏈接:
https://www.tensorflow.org/install
需要在Mac和Windows上安裝Tensorflow或者安裝過程中遇到疑難雜癥的同學也可以查詢該鏈接。關于Jupyter Notebook和Tensorboard插件的問題。
可以查詢鏈接:
http://jupyter.readthedocs.io/en/latest/install.html?
https://github.com/lspvic/jupyter_tensorboard
現在打開jupyter notebook命令輸出中的鏈接,就可以瀏覽器里編寫Tensorflow程序了。為了盡快上手,我們先跳過Tensorflow的基礎概念,直接運行一個來自?https://github.com/sankit1/cv-tricks.com?的小Demo。
首先我們點擊Jupyter Notebook Files標簽頁右上角的New按鈕創建一個Python 3 記事本。Jupyter Notebook支持以“!”開頭運行本地命令,寫好命令,選中灰色的編輯框(Jupyter Notebook稱其為Cell),點擊工具欄的Run按鈕即可執行。我們首先取出cv-tricks的代碼,再安裝opencv、sklearn、scipy等三個數學工具包。
然后我們再回到Files標簽頁,打開路徑為cv-tricks.com/Tensorflow-tutorials/tutorial-2-image-classifier/train.py的Python文件。
由于這種打開方式是不能運行代碼的,所以我們再創建一個Python 3記事本,把train.py的文件內容復制過來,然后執行。
相信此時一定有好學的同學到cv-tricks的GitHub里去看了,可能有人會發現里面有training_data和testing_data兩個目錄,里面有很多貓貓狗狗的照片,實際上train.py在做的事情就是創建一個卷積神經網絡,然后讀入training_data目錄下的貓狗照片進行如何區分貓狗的訓練。
通過程序的輸出我們可以看到識別的準確度從最開始的50%逐步上升、直至收斂。50%的準確度即為瞎猜,這個輸出很直觀的展現了機器學習的過程。
這個程序需要跑上一段時間,根據機器的性能不同和室內溫度,半小時到一小時都有可能,同學們在自己進行實驗的時候請耐心等待。另外,GitHub上的代碼有個小bug,這里故意不說,相信細心的同學都能知道如何修改。
程序運行過程中會生成幾個文件,就是Tensorflow的模型文件,里面存儲的就是訓練好的神經網絡,后面就用這些文件去區分貓狗。
等訓練結束之后,我們可以用predict.py加載這個模型,用它識別一些網上找來的貓狗圖片。
識別效果還算可以,如果有同學在自己的測試里發現識別出錯,那也很正常,畢竟這只是一個很簡單的Demo,訓練數據很少,訓練時間也很短,準確率做不到太高。
現在我們的第一個AI程序就跑起來了,“單機版”的AI實驗室建設完畢。
三、搭建“高階版”的AI實驗室
接下來才是本次課程的重頭戲——AI實驗室的“高階版”。
正如前文所述,AI實驗室的“高階版”是一個分布式訓練環境,一來可以進行多機并行訓練以提高訓練速度,二來可以通過多租戶方式集約化的使用資源,適合學校、企業中的小團隊一起使用。
“高階版”的AI實驗室底層使用了Kubernetes和Docker,我們公眾號的老朋友應該對這兩個東西都比較了解,如果有同學不了解那也沒關系,暫且把它們當作一個支撐Tensorflow分布訓練的資源調度器就好。整體架構見下圖:
說到這里,我們需要介紹一下和Tensorflow分布式訓練有關的一些概念,首先是兩種訓練方式——數據并行和模型并行:
其次數據并行又分為同步數據并行和異步數據并行:
現階段我們推薦使用同步數據并行方式,所以各位同學暫且對其他三個概念有些印象即可,以后碰到的時候再深入研究也不遲。
接下來介紹搭建“高階版”AI實驗室的步驟,要比“單機版”復雜不少。首先需要準備幾臺服務器,并在各服務器上安裝64位的Ubuntu 16.04或更高版本。
如果只有一臺服務器那也沒關系,本課程介紹的方法有一個很大的優勢就是可擴展性,可以先一臺服務器湊合用,等以后富裕了、服務器多了,再添加進來也很容易。但是安裝后一定要注意以下三點:
各服務器的Hostname、MAC地址和product_uuid(/sys/class/dmi/id/product_uuid)要唯一。
各服務都要關閉Swap,方法是在/etc/fstab中將Swap行注釋掉。
各服務器都要關閉防火墻,方法是執行ufw disable命令。
然后各服務器重啟,使上述修改生效。
準備工作完成后即可開始安裝Docker和Kubernetes的集群部署工具Kubeadm,每臺服務器上都要裝,分為三步:
cat </etc/apt/sources.list.d/kubernetes.list
deb?http://apt.kubernetes.io/?kubernetes-xenial main
EOF
apt-get update
apt-get install -y apt-transport-https curl
apt-get install -y docker.io kubeadm kubelet kubectl
接下來是初始化管理節點,選一臺你最喜歡的服務器完成以下步驟,如果你只有一臺服務器,那這臺就既做管理節點也做工作節點。
如果你使用的是root用戶,則需要設置環境變量:
export KUBECONFIG=/etc/kubernetes/admin.conf
為了日后方便,可以將該環境變量添加到shell的profile中。
a) 首先修改一個網絡參數,執行命令sysctl net.bridge.bridge-nf-call-iptables=1,并將其添加到/etc/sysctl.conf文件中。
b) 安裝Kubernetes的網絡虛擬化add-on,執行命令:
過程中還是會遇到“你懂的”問題……
上述步驟完成之后,管理節點就初始化成功了,如果有同學覺得單獨用一臺服務器做管理節點有點浪費,或者是有同學只有一臺服務器,既要做管理節點又要做工作節點,那么請執行命令:kubectl taint nodes --all node-role.kubernetes.io/master-。
接下來要做的就是添加工作節點了,剛才執行kubeadm init命令的時候輸出里有一行內容類似于:
kubeadm join --token <token> <master-ip>:<master-port> --discovery-token-ca-cert-hash sha256:<hash>把這行復制到其他服務器上用root用戶執行,即可將這臺服務器作為工作節點添加到集群之中,只有一臺服務器的同學可以等富裕了之后再執行。
到此一個Kubernetes集群就完成了,如果有同學在操作過程中遇到疑難雜癥。
請查詢鏈接:
https://kubernetes.io/docs/tasks/tools/install-kubeadm/?
https://kubernetes.io/docs/setup/independent/create-cluster-kubeadm/
接下來要做的就是安裝Kubeflow了,還記得這個是什么嗎?前文提過,Kubeflow就是Google提供的整合Kubernetes和Tensorflow的一站式AI開源方案。由于Kubeflow使用了ksonnet作為部署工具,所以我們首先要到https://ksonnet.io/#get-started下載ksonnet的命令行工具。這里順便提一句,ksonnet是個非常強大的工具,也比較復雜,感興趣的同學可以查看他們的官網探明究竟,這里我們就不展開講解了。
現在我們開始配置kubeflow,步驟比較多。
初始化工作目錄,目錄名為AILab_Advanced,執行命令:
ks init AILab_Advanced創建配置文件模板,需要以下步驟:
切換工作目錄,執行命令:cd AILab_Advanced
下載基本配置文件,執行以下命令:
這里我們使用的是0.1.2版本,過段時間會發布0.2版本,各位同學可以根據需要修改VERSION變量的值。
創建配置文件模板,執行命令:
ks generate core kubeflow-core --name=kubeflow-core
創建Kubeflow基礎服務,需要的步驟:
創建名為AILab的運行環境,執行命令:
ks env add AILab
創建名為AILab的租戶,執行命令:
kubectl create namespace AILab
創建kubeflow基礎服務,執行以下命令:
ks env set AILab --namespace AILab
ks apply AILab -c kubeflow-core
創建過程中依然需要下載幾個Docker鏡像,各位同學在操作過程中請耐心等待。
上述步驟執行完畢后,AI實驗室的”高階版”就基本完工了,可以通過瀏覽器使用,訪問前需要映射一下端口,執行下面兩條命令:
PODNAME=`kubectl get pods --namespace=AILab --selector="app=tf-hub" \ --output=template --template="{{with index .items 0}}{{.metadata.name}}{{end}}"` kubectl port-forward --namespace=AILab $PODNAME 8000:8000然后就可以通過8000端口訪問了,首頁如下圖:
因為這里沒有啟用安全模式,所以用戶名和密碼可以隨便填。AI實驗室的“高階版”是支持多用戶的,會為不同的用戶名啟動獨立的實驗環境,登錄后的效果如下圖:
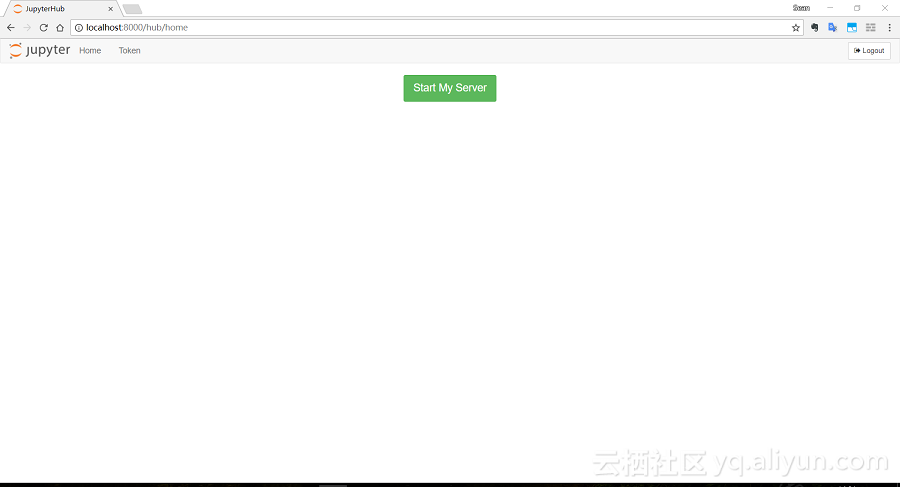點擊Start My Server按鈕即可啟動自己的Jupyter Notebook:
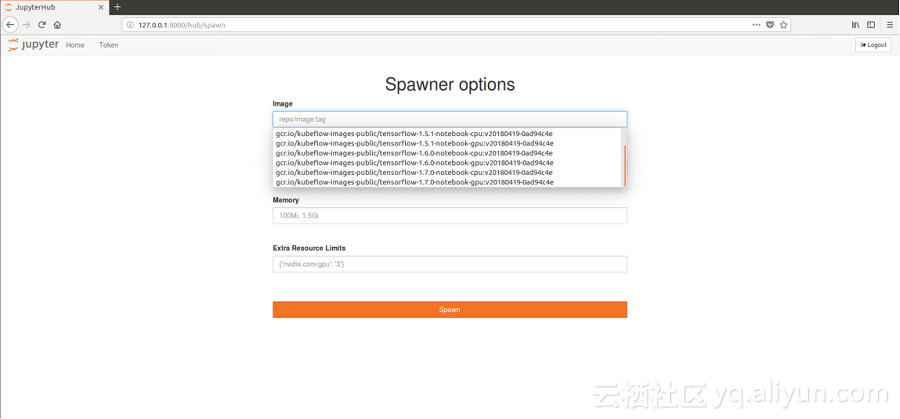這里可以選擇你喜歡的Tensorflow版本,并填寫所需的資源參數。這些鏡像都比較大,下載的時間會比較久。
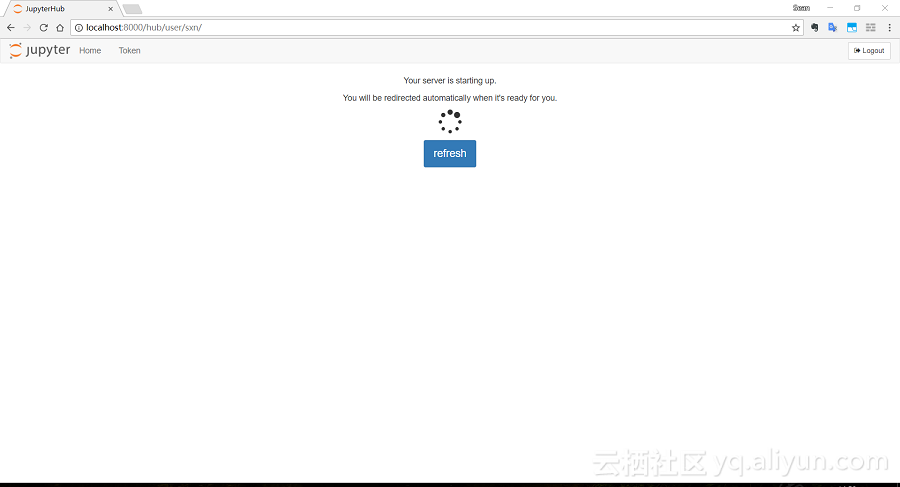由于首次啟動需要下載鏡像,如果網絡環境不好,這一步很可能會超時失敗,但是后臺的鏡像下載不會中斷,等下載完成,再去啟動Jupyter Notebook就很快了。此時會出現我們熟悉的Jupyter Notebook首頁:
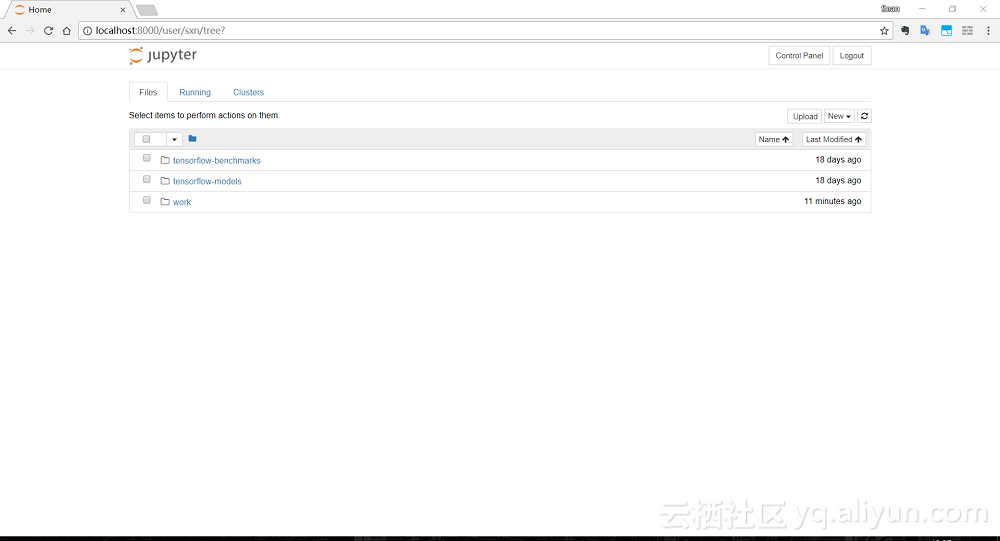現在我們就可以像在“單機版”里那樣編寫代碼了。每個Jupyter Notebook都運行在一個獨立的Docker容器中,用戶之間不會互相干擾,還可以通過New按鈕創建一個Terminal,登陸到容器內部操作。
前面稍微展示了一下如何使用這個“多租戶”的Jupyter Notebook,接下來開始介紹如何發起Tensorflow的分布式訓練。Kubeflow提供了一個分布式訓練的發起頁面,在該頁面填寫訓練名稱、鏡像地址、入口程序、所需資源和節點數等參數即可發起訓練,如下圖所示:
發起訓練之后還可以通過Web頁面查看運行狀態,在這個頁面中可以看到kubeflow通過鏡像創建了一系列的容器,每個容器即為訓練集群的一個節點。
這里使用了一個Google提供的測試鏡像,我們也可以自己制作鏡像,只需要在“多租戶”的Jupyter Notebook里把程序調試好,然后把該Jupyter Notebook所在的容器保存成一個Docker鏡像即可。
另外需要注意的是,在編寫Tensorflow程序的時候,也需要為分布式環境做一些適配。Tensorflow使用一個名為tf.train.ClusterSpec的constructor描述訓練集群結構,由于在“高階版”的AI實驗室中,集群結構是在發起分布式訓練的時候動態設置的,所以就不能像以前那也寫死在代碼里,需要對代碼做一些修改,如下圖所示:
這里的關鍵是名為TF_CONFIG的環境變量,kubeflow里有個有個名為tf-operator的組件,可以把它當成一個Tensorflow和Kubernetes之間的適配器,它的作用之一就是在發起分布式訓練時將集群結構寫到TF_CONFIG這個環境變量里,訓練集群的每個節點里都會寫,然后就可以在程序中通過讀取這個變量來動態配置集群結構了。
各位同學可以參考鏈接:
https://github.com/kubeflow/tf-operator/blob/master/examples/tf_sample/tf_sample/tf_smoke.py
中的實例代碼,試著把前面“單機版”的貓狗識別程序改成分布式,成功后一定會很有成就感。
到此“高階版”的AI實驗室就介紹完畢了,一定有同學會覺得這個實驗室比較簡陋。確實如此,一來是kubeflow還處于非常早期的開發階段,二來是一個完善的AI實驗室還需要在kubeflow之上做很多產品化工作。
我司目前也在做這方面的工作,計劃把AI實驗室和我司的云平臺產品整合起來,形成一個AI實驗室云服務,總體架構如下圖所示:
并在此之上構建AI生態:
原文發布時間為:2018-07-05
本文作者: 宋瀟男
本文來自云棲社區合作伙伴“EAWorld”,了解相關信息可以關注“EAWorld”。
總結
以上是生活随笔為你收集整理的一起来DIY一个人工智能实验室吧的全部內容,希望文章能夠幫你解決所遇到的問題。

- 上一篇: Java学习笔记 (二十七) 使用NIO
- 下一篇: 如何在Mac上创建水彩画?Art Tex