人工智能:一种现代的方法 书本课后习题解答
文章目錄
- 摘要
- 更新:課本及習(xí)題答案下載
- 第一章——緒論
- 1.1 用自己的語言定義(1)智能,(2)人工智能,(3)Agent,(4)理性,(5)邏輯推理。
- 1.2 反射行動(如從熱爐子上縮手)是理性的嘛?是智能的嘛?
- 第二章——智能Agent
- 2.2
- 2.3
- 3.第三章
- 3.3
- 3.4
- 3.5
- 3.6
- 3.7
- 3.8
- 3.9 找出一個狀態(tài)空間,使用迭代加深搜索比深度優(yōu)先搜索的性能要差很多(如,一個是$O(n^2)$,另一個是O(n))。
- 3.10
- 第四章 超越經(jīng)典搜索
- 4.2
- 4.3
- 第五章——對抗搜索
- 5.1 對alpha-beta剪枝的理解
- 5.2
- 5.3
- 第六章 約束滿足問題
- 6.1 地圖著色問題有多少個解?
- 6.2
- 6.3
- 6.4
- 第七章 邏輯Agent
- 7.1
- 7.2
- 7.3
- 7.4
- 第八章 一階邏輯
- 8.1
- 8.2
- 8.3
- 8.4
- 8.5
- 第九章——一階邏輯的推理
- 9.2
- 第十章——經(jīng)典規(guī)劃
- 10.1 問題求解和規(guī)劃之間的不同和相似之處
- 10.2
- 10.3 證明PDDL問題的后向搜索是完備的
- 10.4 為什么在規(guī)劃問題中去掉每個動作模式的負(fù)效果會得到一個松弛問題
- 第十一章——現(xiàn)實世界的規(guī)劃與行動
- 11.1 暫無,這一章有點難,我有空再加。
- 第十三章——不確定性的量化
- 13.1 貝葉斯規(guī)則
- 13.2 使用概率公理證明:一個離散隨機變量的任何概率分布,總和等于1
- 13.3
- 13.4
- 第十四章——概率推理
- 資源下載
- 文末詩詞
- 參考文獻(xiàn)
摘要
本文旨在呈現(xiàn)《人工智能:一種現(xiàn)代的方法》中的一些經(jīng)典、有趣的習(xí)題。
《人工智能:一種現(xiàn)代的方法》的習(xí)題答案可以在我的CSDN資源頁下載
更新:課本及習(xí)題答案下載
第一次寫作時間:2018年07月08日 21:57:42
更新時間:2018年12月3日21:33:05
看到很多網(wǎng)友評論,發(fā)現(xiàn)大家對課本及習(xí)題答案的需求不小,然而CSDN無法上傳這樣的資料,所以這里建立一個百度云鏈接,大家可以自取,祝大家學(xué)習(xí)進(jìn)步,考研的同學(xué)考研順利:
鏈接:https://pan.baidu.com/s/19KGXMLv-WVHHfFfpVJ6VnA
提取碼:eku2
第一章——緒論
1.1 用自己的語言定義(1)智能,(2)人工智能,(3)Agent,(4)理性,(5)邏輯推理。
答:1)Intelligence:the ability to apply knowledge in order to perfrom better in an environment.
2)Artificial intelligence: the study and construction of agent programs that perform well in a given environment, for a given agent architecture.
3)Agent: an entity that takes action in response to percepts from an environment.
4)理性:the property of a system which does the “right thing” given what it knows.
5)邏輯推理:the a process of deriving new sentences from old, such that the new sentences are necessarily true if the old ones are true.
1.2 反射行動(如從熱爐子上縮手)是理性的嘛?是智能的嘛?
答:是理性的。because slower, deliberative actions would tend to result in more damage to the hand.
不是智能的。If “intelligent” means “applying knowledge” or “using thought and reasoning” then it does not require intelligence to make a reflex action.
第二章——智能Agent
###2.1
 **圖2.1 習(xí)題2.1**答:1)錯。Perfect rationality refers to the ability to make good decisions given the sensor information received.
2)對。純反射agent忽略之前的感知信息,所以在部分可感知的環(huán)境中是不能達(dá)到一個最優(yōu)的狀態(tài)估計的。For example, correspondence chess is played by sending moves; if the other player’s move is the current percept, a reflex agent could not keep track of the board state and would have to respond to, say, “a4” in the
same way regardless of the position in which it was played.
3)對。For example, in an environment with a single state, such that all actions have the same reward, it doesn’t matter which action is taken. More generally, any environment that is reward-invariant under permutation of the actions will satisfy this property.
4)錯。The agent function, notionally speaking, takes as input the entire percept sequence up to that point, whereas the agent program takes the current percept only.
5)錯。For example, the environment may contain Turing machines and input tapes and the agent’s job is to solve the halting problem; there is an agent function that specifies the right answers, but no agent program can implement it. Another example would be an agent function that requires solving intractable problem instances of arbitrary size in constant time.
圖靈停機問題參考:[1]
6)對。This is a special case of (3); if it doesn’t matter which action you take, selecting randomly is rational
7)對。For example, we can arbitrarily modify the parts of the environment that are unreachable by any optimal policy as long as they stay unreachable
8)錯。Some actions are stupid—and the agent may know this if it has a model of the environment—even if one cannot perceive the environment state.
9)錯。Unless it draws the perfect hand, the agent can always lose if an opponent has better cards. This can happen for game after game. The correct statement is that the agent’s expected winnings are nonnegative.
2.2
 **圖2.2.1 習(xí)題2.2**  **圖2.2.2 答案2.2**2.3
**圖2.3.1 問題2.3**答:
Agent:an entity that perceives and acts; Essentially any object qualifies; the key point is the way the object implements an agent function.
Agent function: a function that specifies the agent’s action in response to every possible percept sequence.
Agent program: that program which, combined with a machine architecture, implements an agent function. In our simple designs, the program takes a new percept on each invocation and returns an action.
Rationality: a property of agents that choose actions that maximize their expected utility, given the percepts to date.
Autonomy: a property of agents whose behavior is determined by their own experience rather than solely by their initial programming.
Reflex agent: an agent whose action depends only on the current percept.
Model-based agent: an agent whose action is derived directly from an internal model of the current world state that is updated over time.
Model-based agent: an agent whose action is derived directly from an internal model of the current world state that is updated over time.
Utility-based agent: an agent that selects actions that it believes will maximize the expected utility of the outcome state.
Learning agent: an agent whose behavior improves over time based on its experience.
3.第三章
###3.1 為什么問題的形式化要在目標(biāo)的形式化之后?
答:目標(biāo)形式化中,我們決定對世界的哪些方面感興趣
這樣的話,在問題形式化里面,我們就能直接決定留哪些東西,操作哪些。
###3.2
 **圖3.2.1 問題3.2**  **圖3.2.2 答案3.2**之所以記錄這個問題,是因為我對這個(b)問題比較感興趣:有關(guān)可采納函數(shù)的判斷(不能高估實際花銷)。
3.3
 **圖3.3.1 問題3.3**  **圖3.3.2 答案3.3**記錄這個問題,因為它的推導(dǎo)很巧妙,很有意思,而且非常之詳細(xì),讓人不禁生出記錄稱贊的想法。
###3.4 野人和傳教士問題
和3.2的形式化問題差不多。多了一個:要檢查重復(fù)狀態(tài)的操作。
具體答案+代碼在 [2]
3.4
 **圖3.4.1 問題3.4**答:
state 狀態(tài):A state is a situation that an agent can find itself in. We distinguish two types of states: world states (the actual concrete situations in the real world) and representational states (the abstract descriptions of the real world that are used by the agent in deliberating about what to
do)
state space 狀態(tài)空間:A state space is a graph whose nodes are the set of all states, and whose links are actions that transform one state into another
search tree 搜索樹: is a tree (a graph with no undirected loops) in which the root node is the start state and the set of children for each node consists of the states reachable by taking any action.
search node 搜索節(jié)點:is a node in the search tree.
goal 目標(biāo):a state that the agent is trying to reach
action 行動:something that the agent can choose to do.
successor function 后繼函數(shù):a successor function described the agent’s options: given a state, it returns a set of (action, state) pairs, where each state is the state reachable by taking the action.
** branching factor 分支因子**:The branching factor in a search tree is the number of actions available to the agent
3.5
 **圖3.5.1 問題3.5**  **圖3.5.2 答案3.5**這道題有一個很有意思的想法:拋棄序列結(jié)構(gòu)(壓扁狀態(tài)空間),即把一些動作都組合起來,變成一個超級行動。這樣的話整個搜索樹深度為1.
壞處,如果發(fā)現(xiàn)Go中的第一個行動(unplug your battery)不是解,很難把后面也含這個行動的整合行動給排除掉。
3.6
 **圖3.6.1 問題3.6**  **圖3.6.2 答案3.6**這些判斷題也很有意思,但是答案的(c)應(yīng)該是false。作者寫錯了。
3.7
 **圖3.7.1 問題3.7**   **圖3.7.2 答案3.7**3.8
 **圖3.8.1 問題3.8**  **圖3.8.2 答案3.8**為什么要放這道題?因為答案有錯誤的地方,狀態(tài)空間應(yīng)該是n2?2n2n^2*2^{n^2}n2?2n2
3.9 找出一個狀態(tài)空間,使用迭代加深搜索比深度優(yōu)先搜索的性能要差很多(如,一個是O(n2)O(n^2)O(n2),另一個是O(n))。
答:Consider a domain in which every state has a single successor, and there is a single goal
at depth n. Then depth-first search will find the goal in n steps, whereas iterative deepening
search will take 1 + 2 + 3 + · · · + n = O(n2)O(n^2)O(n2) steps
3.10
 **圖3.10.1 問題3.10**  **圖3.10.2 答案3.10**第四章 超越經(jīng)典搜索
###4.1 在不確定、部分可觀察的環(huán)境中,Agent怎么達(dá)成目標(biāo)?
答:在完全可觀察的、確定的環(huán)境下,Agent可以準(zhǔn)確地計算出經(jīng)過任何行動序列之后能達(dá)到什么狀態(tài),Agent總是知道自己處于什么狀態(tài),其傳感器一開始告知agent初始狀態(tài),而在行動之后無需提供新的信息。
如果部分可觀察、不確定,感知信息就變得非常有用了。
部分可觀察:每個感知信息都可能縮小Agent可能的狀態(tài)范圍,這樣也就使得Agent更容易達(dá)到目標(biāo)。
環(huán)境不確定:感知信息告訴Agent某一行動的結(jié)果到底是什么。
在這兩種情況中。問題的解不是一個序列(因為沒法預(yù)知未來信息,Agent的未來行動依賴于未來感知信息),而是一個應(yīng)急規(guī)劃(也叫:策略)
應(yīng)急規(guī)劃描述了根據(jù)接收到的感知信息來決定行動。
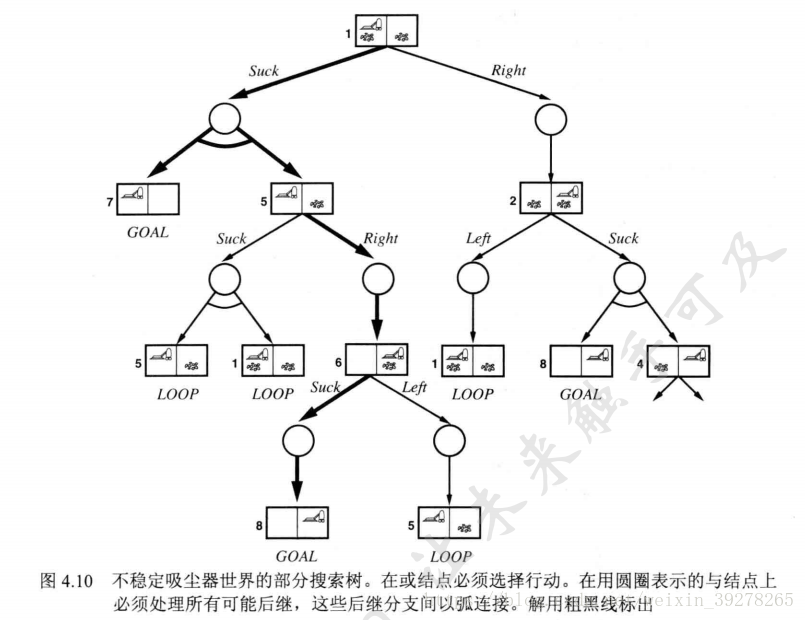 **圖4.1 與或圖搜索**在圖中,在或節(jié)點給行動,與節(jié)點考慮所有后繼。
4.2
 **圖4.2.1 問題4.2**答案:
a)爬山法
b)寬度優(yōu)先。Local beam search with one initial state and no limit on the number of states retained, resembles breadth-first search in that it adds one complete layer of nodes before adding the next layer. Starting from one state, the algorithm would be essentially identical to breadth-first search except that each layer is generated all at once.
c)Simulated annealing with T = 0 at all times: ignoring the fact that the termination step would be triggered immediately, the search would be identical to first-choice hill climbing because every downward successor would be rejected with probability 1. (Exercise may be modified in future printings.)
d)Simulated annealing with T = ∞ at all times is a random-walk search: it always accepts a new state.
e)Genetic algorithm with population size N = 1: if the population size is 1, then the two selected parents will be the same individual; crossover yields an exact copy of the individual; then there is a small chance of mutation. Thus, the algorithm executes a random walk in the space of individuals.
4.3
 **圖4.3.1 問題4.3**  **圖4.3.2 答案4.3**###4.4 用局部搜索中的爬山法求解TSP問題
答:
· Connect all the cities into an arbitrary path.
· Pick two points along the path at random.
· Split the path at those points, producing three pieces.
· Try all six possible ways to connect the three pieces.
· Keep the best one, and reconnect the path accordingly.
· Iterate the steps above until no improvement is observed for a while.
第五章——對抗搜索
5.1 對alpha-beta剪枝的理解
參考[3](提出了一個下界,鉗制值的觀點,我覺得比較有意思)
但是主要還是要參考書本上的例子和算法(偽代碼),照著算法和例子走一遍程序就比較好理解了。
5.2
 **圖1 問題5.2**  **圖2 答案5.2-部分**兩個八數(shù)碼問題。
形式化該問題:1)初始狀態(tài):兩個隨機地8數(shù)碼 2)后繼函數(shù):在一個未解決的puzzle上做移動 3)目標(biāo)測試:兩個問題都達(dá)到目標(biāo)狀態(tài) 4)cost 移動步數(shù)。
這里有必要介紹一下八數(shù)碼的狀態(tài)空間 [4]
對于八數(shù)碼問題的解決,首先要考慮是否有答案。每一個狀態(tài)可認(rèn)為是一個1×9的矩陣,問題即通過矩陣的變換,是否可以變換為目標(biāo)狀態(tài)對應(yīng)的矩陣?由數(shù)學(xué)知識可知,可計算這兩個有序數(shù)列的逆序值,如果兩者都是偶數(shù)或奇數(shù),則可通過變換到達(dá),否則,這兩個狀態(tài)不可達(dá)。這樣,就可以在具體解決問題之前判斷出問題是否可解,從而可以避免不必要的搜索。
如果初始狀態(tài)可以到達(dá)目標(biāo)狀態(tài),那么采取什么樣的方法呢?
常用的狀態(tài)空間搜索有深度優(yōu)先和廣度優(yōu)先。廣度優(yōu)先是從初始狀態(tài)一層一層向下找,直到找到目標(biāo)為止。深度優(yōu)先是按照一定的順序前查找完一個分支,再查找另一個分支,以至找到目標(biāo)為止。廣度和深度優(yōu)先搜索有一個很大的缺陷就是他們都是在一個給定的狀態(tài)空間中窮舉。這在狀態(tài)空間不大的情況下是很合適的算法,可是當(dāng)狀態(tài)空間十分大,且不預(yù)測的情況下就不可取了。他的效率實在太低,甚至不可完成。由于八數(shù)碼問題狀態(tài)空間共有9!個狀態(tài),對于八數(shù)碼問題如果選定了初始狀態(tài)和目標(biāo)狀態(tài),有9!/2個狀態(tài)要搜索,考慮到時間和空間的限制,在這里采用A*算法作為搜索策略。在這里就要用到啟發(fā)式搜索
5.3
 **圖1 問題5.3-部分**  **圖2 答案5.3-部分**這個問題也比較經(jīng)典,所以在這里記錄了。
第六章 約束滿足問題
6.1 地圖著色問題有多少個解?
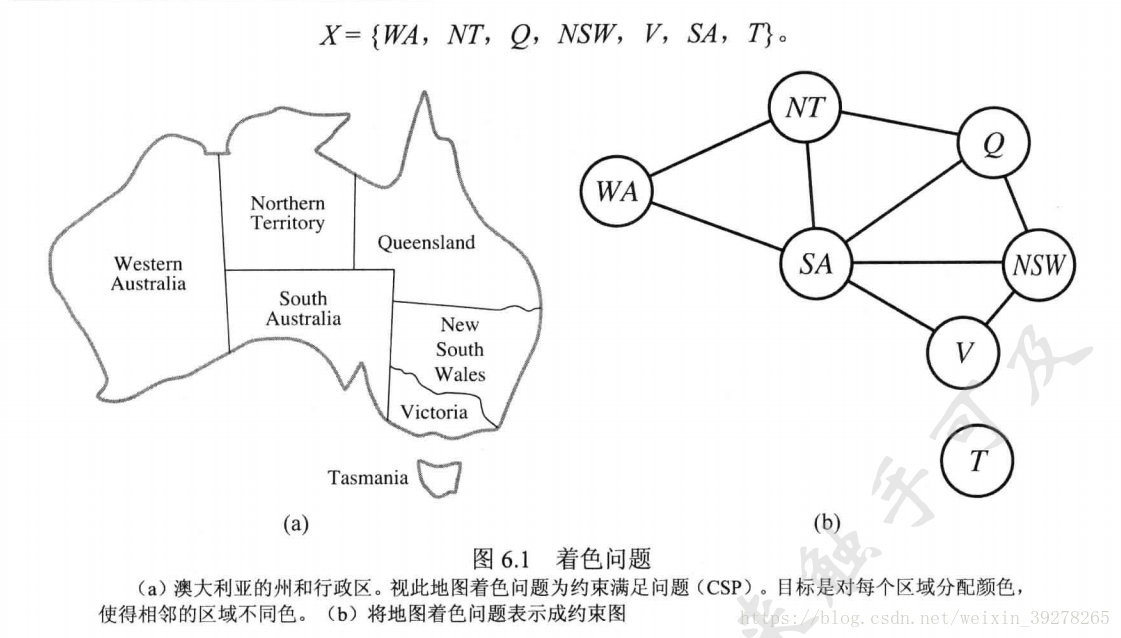 **圖1 問題6.1** 這個用度啟發(fā)式,先找到SA,后面的就好取了。 3*2*3=18個解。6.2
 **圖1 問題6.2**  **圖2 答案6.2**這道題有點像八皇后的變形,答案給了A,B兩種解法,都很有意思的。
6.3
 **圖1 問題6.3**  **圖2 答案6.3**有時候感覺類比過來很麻煩啊,根本想不到。想不通。不是那么簡單明了
這道題的(c)我沒看懂。記錄之。
6.4
 **圖1 問題6.4**答:這道題的答案給出了兩種CSP的形式化定義。
1)25個變量,5個顏色,5個寵物,5個國家,5種飲料,5種香煙。 值就是對應(yīng)的房間號。
2)5個變量,5個房間。值域就是每個房間對應(yīng)的5個屬性。
第七章 邏輯Agent
7.1
 **圖1 問題7.1**答案:只要KB為真的時候,兩個語句為真,那么就是真。
7.2
 **圖1 問題7.2**之所以列出這個問題,是希望舉一反三,用7.1 的方法羅列出所有世界模型即可。
7.3
 **圖1 問題7.3**  **圖2 答案7.3**基本功題目。轉(zhuǎn)成CNF。
7.4
 **圖1 問題7.4**  **圖2 答案7.4**這道題也比較基礎(chǔ)吧,記錄一下。
第八章 一階邏輯
8.1
 **圖1 問題8.1**  **圖2 答案8.1**8.2
 **圖1 問題8.2**  **圖2 答案8.2**一階邏輯推理。
8.3
 **圖1 問題8.3**  **圖2 答案8.3**用一階邏輯表示。
8.4
 **圖1 問題8.4**  **圖2 答案8.4**比較有趣的一個邏輯推理吧。
8.5
 **圖1 問題8.5**  **圖2 答案8.5**最后一問有些難。
第九章——一階邏輯的推理
###9.1 什么是前向鏈接?
從知識庫KB中的原子語句出發(fā),在前向推理中應(yīng)用假言推理規(guī)則,增加新的原子語句,直到不能進(jìn)行任何推理。
9.2
 **圖1 問題9.2** **圖2 答案9.2** 一個存在量詞的代換。第十章——經(jīng)典規(guī)劃
10.1 問題求解和規(guī)劃之間的不同和相似之處
相同:Getting from a start state to a goal using a set of defined operations or actions, typically in a deterministic, discrete, observable environmnet.
不同: In planning, however, we open up the representation of states, goals, and plans, which allows for a wider variety of algorithms that decompose the search space, search forwards or backwards, and use automated generation of heuristic functions.
10.2
 **圖1 問題10.2**  **圖2 答案10.2**10.3 證明PDDL問題的后向搜索是完備的
答:Briefly, the reason is the same as for forward search: in the absence of function symbols, a PDDL state space is finite. Hence any complete search algorithm will be complete for PDDL planning, whether forward or backward
10.4 為什么在規(guī)劃問題中去掉每個動作模式的負(fù)效果會得到一個松弛問題
答:Goals and preconditions can only be positive literals. So a negative effect can only make it harder to achieve a goal (or a precondition to an action that achieves the goal). Therefore, eliminating all negative effects only makes a problem easier. This would not be true if negative preconditions and goals were allowed.
第十一章——現(xiàn)實世界的規(guī)劃與行動
11.1 暫無,這一章有點難,我有空再加。
第十三章——不確定性的量化
13.1 貝葉斯規(guī)則
**圖1 答案13.1**13.2 使用概率公理證明:一個離散隨機變量的任何概率分布,總和等于1
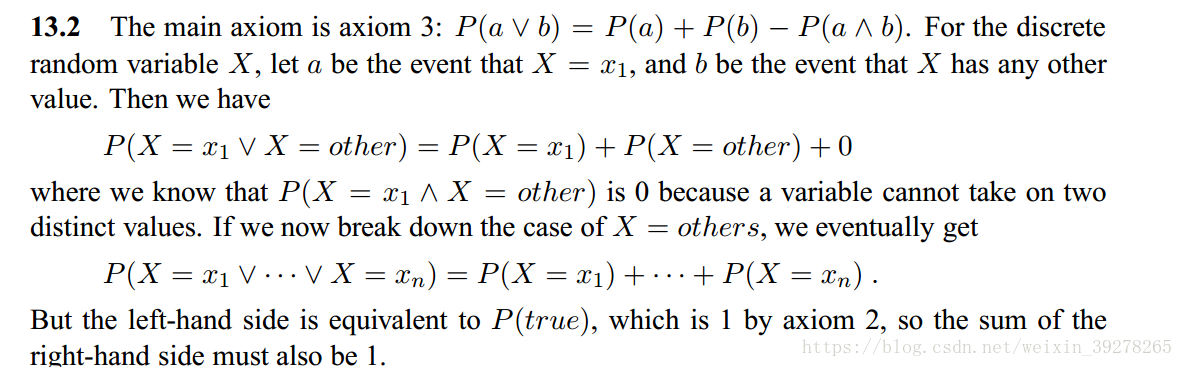 **圖1 答案13.2**我覺得這道題還有有意思的,這里記錄一下。
13.3
 **圖1 問題13.3**  **圖2 答案13.3**13.4
 **圖1 問題13.4**  **圖2 答案13.4**一個文本分類的簡單變形。
第十四章——概率推理
###14.1
 **圖1 問題14.1**   **圖2 答案14.1**資源下載
如果想瀏覽全部答案,可以到我的CSDN資源頁下載.
文末詩詞
子規(guī)夜半猶啼血,不信東風(fēng)喚不回。 ——王令《送春》參考文獻(xiàn)
[1] 圖靈停機問題(halting problem). https://blog.csdn.net/MyLinChi/article/details/79044156
[2] 傳教士野人過河問題. https://blog.csdn.net/aidayei/article/details/6768696
[3] α-β剪枝算法. https://blog.csdn.net/luningcsdn/article/details/50930276
[4] 八數(shù)碼問題. https://www.cnblogs.com/guanghe/p/5485816.html
總結(jié)
以上是生活随笔為你收集整理的人工智能:一种现代的方法 书本课后习题解答的全部內(nèi)容,希望文章能夠幫你解決所遇到的問題。

- 上一篇: 【学习】人工智能:一种现代的方法
- 下一篇: 广数系统u盘支持什么格式_数控车床编程导